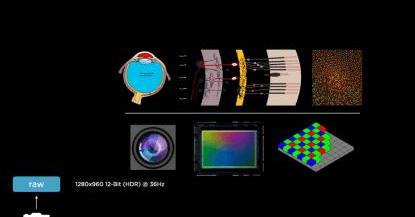
12月10日,特斯拉在北京举办了主题为“自动驾驶仿生大脑”的“T-talk”线下分享研讨会。特斯拉主要讲解了AI技术的最新进展,包括特斯拉如何以纯视觉方案实现精准的自动驾驶能力,带来比雷达+视觉融合方案更安全可靠的体验,以及独特的智能算法等独家内容,引领与会者深入了解特斯拉在自动驾驶领域的探索。坚持视觉感知,用AI神经网络技术提升辅助驾驶能力如图1所示。安德烈说:“我们希望建立一个类似于动物视觉皮层的神经网络连接,来模拟大脑信息输入和输出的过程。就像光线进入视网膜一样,我们希望通过相机模拟这一过程。”
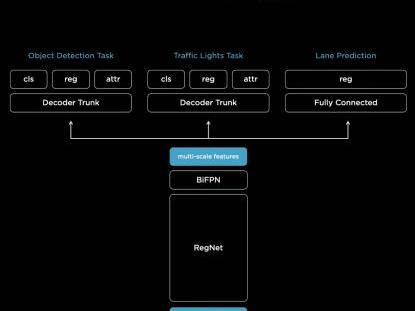
相机模拟人类图像处理流程,以指示多任务学习神经网络架构。八个摄像头传输的原始数据通过一个骨干网络进行处理,利用RegNet残差网络和BiFPN算法模型进行统一处理,得到各种不同精度的图像特征,供不同需求的神经网络任务使用。
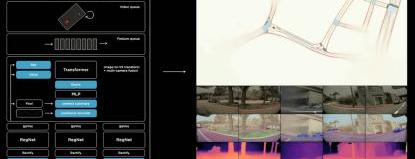
HydraNets是一种多任务学习神经网络架构,由于它处理的是单个相机的单帧图像,因此在实际应用中遇到了许多瓶颈。因此,在二级结构中加入了Transformer神经网络结构,使得原来提取的二维图像特征变成了由多个摄像头组装的三维向量空间的特征,从而大大提高了识别率和准确率。还没有,因为还是单帧画面,所以需要时间维度和空间维度,让车辆具备特征“记忆”功能,以应对“遮挡”、“路牌”等各种场景,最终以视频流的形式实现行驶环境的特征提取,形成向量空间,让车辆低延迟的准确判断周围环境,形成4D向量空间。这些视频特征的数据库是自动用于训练的。
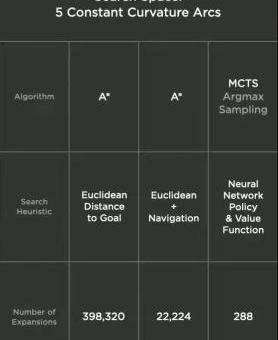
视频4D向量空间的神经网络架构然而,由于城市自动驾驶和高速自动驾驶的区别,车辆规划模块存在两大问题。一个是驾驶方案不一定有最优解,它的局部最优解会很多,也就是说在同样的驾驶环境下,自动驾驶可以选择很多可能的解,而且都是好的解;其次,维度高,车辆不仅需要做出即时反应,还需要对下一段时间进行规划,预估位置、空间、速度、加速度等大量信息。因此,特斯拉选择了两种方式来解决规划模块的两大问题。一种是通过离散搜索求解局部最优解的“答案”,以每1.5毫秒2500次搜索的超级效率执行;另一种是利用连续函数优化来解决高维问题。通过离散搜索得到一个全局最优解,然后通过不断的函数优化平衡舒适性、乘坐舒适性等多个维度的需求,得到最终的规划路径。另外,除了为自己规划之外,还要对其他物体的规划进行“预估”和猜测,即以同样的方式,基于对其他物体的识别和速度、加速度等基本参数,再为其他车辆规划路径,并做出相应的反应。但是,世界各地的路况千变万化,非常复杂。如果采用离散搜索方式,会消耗大量资源,决策时间过长。所以选择深度神经网络和蒙特卡罗搜索树相结合,大大提高了决策效率,几乎一个数量级。
不同模式下效率最终规划模块的整体架构如图5所示。首先将数据处理到一个基于纯视觉方案架构的4D向量空间,然后基于之前获得的物体识别和共享特征数据,利用深度神经网络寻找全局最优解,将最终的规划结果交给执行器执行。
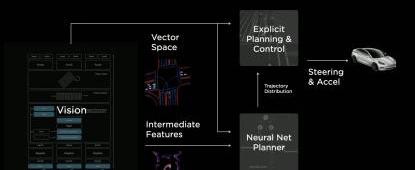
视觉识别+规划,实施整体架构,当然再好的神经网络架构和处理方法,都离不开一个有效而庞大的数据库。在从2D到3D、4D的数据转换过程中,1000多人的人工标注团队也在与时俱进地在4D空间进行标注,在矢量空间标注后,会自动映射成不同摄像头的特定单幅图像,大大增加了数据标注量,但这些还远远不够,人工标注的数据量远远不够自动驾驶所需的训练。

4D向量空间手动标注演示由于人更擅长语义识别,而计算机更擅长几何、三角剖分、跟踪和重建,特斯拉想创造一种人与计算机“和谐分工”的模式。特斯拉建立了一个庞大的自动标注管道,使用45秒-1分钟的视频,包括大量的传感器数据,交给神经网络进行离线学习,然后使用大量的机器和人工智能算法生成可以用来训练网络的标注数据集。

视频剪辑的自动标记过程用于识别可驾驶区域,例如道路、车道、十字路口等。特斯拉使用NeRF“神经辐射场”,即一种将2D转换为3D的图像处理算法,给出已建立的XY坐标点数据,使神经网络可以预测地面的高度,从而生成无数的XYZ坐标点和各种语义,如路边、车道线、路面等。,形成大量信息点,投射回相机屏幕。然后将道路数据与前面神经网络识别出的分割结果进行对比,整体优化所有摄像头的图像;同时结合时间维度和空间维度,营造出相对完美的重建场景。

道路重建演示就是利用这种技术,对经过同一地点的不同车辆所重建的道路信息进行交叉比对。只有所有的位置信息都一致,预测才是正确的。在共同作用下,形成了一种有效的路面标注方法。

多视频数据标注相互重叠,相互检查,与高精地图完全不同。只要所有视频片段生成的标注信息越来越准确,与视频中的实际路况一致,就没有必要维护这些数据。同时,利用这些技术,可以对静态物体进行识别和重建,并根据这些有无纹理的3D信息点对其进行标注。这些标记点对于摄像机识别任何障碍物非常有用。

对这些数据进行离线处理,并对静态物体进行3D信息点重建的另一个好处是,自行车网络一次只能预测其他运动的东西,而离线可以因为已经建立的数据而熟悉过去和未来,可以根据确定的数据预测、标定和优化所有物体的速度和加速度,无论遮挡与否,并对其进行标记。训练网络后期可以更准确的判断其他移动的东西,方便规划模块进行规划。
0
离线校对并标记车辆和行人的速度和加速度,然后将这些结合起来,形成视频数据中所有与道路相关的静态和动态物体的识别、预测和重建,并标记其动态数据。
1
视频片段对周围环境的重构和标注将成为训练自动驾驶神经网络的核心部分。其中一个项目就是用这些数据在三个月内训练好网络,成功实现毫米波雷达的所有功能,并且更加精确,于是去掉了毫米波雷达。
2
在摄像头几乎看不到的情况下,对速度和距离的判断仍然准确验证了这种方法的高效性,因此需要大量的视频数据进行训练。所以与此同时,特斯拉还开发了“模拟场景技术”,可以模拟现实中不常见的“边缘场景”进行自动驾驶训练。如图4所示,在仿真场景中,特斯拉工程师可以提供不同的环境和其他参数(障碍物、碰撞、舒适度等。),大大提高了训练效率。
3
模拟场景特斯拉已经使用模拟模式来训练网络。它已经使用了3亿张图片和50亿个标签来训练网络,并将继续使用这种模式来解决更多的问题。
4
模拟模式带来的提升,以及未来几个月的期待,综上所述,要想更快的提升自动驾驶网络的能力,需要处理大量的视频片段和操作。举个简单的例子,为了去掉毫米波雷达,处理了250万个视频片段,生成了100多亿个标注;而这些使得硬件越来越成为发展速度的瓶颈。此前,特斯拉使用了一套约3000个GPU、略少于20000个CPU的训练硬件,并增加了2000多台FSD计算机进行模拟。后来发展成为由10000个GPU组成的世界排名第五的超级计算机,但即便如此,仍然远远不够。
5
目前在用的超级计算机的参数和变化,所以特斯拉决定自己研发超级计算机。“工程开山之作”——D1芯片和Dojo超级计算机目前,随着待处理数据的指数级增长,特斯拉也在提高训练神经网络的计算能力,于是有了特斯拉Dojo超级计算机。特斯拉的目标是在人工智能训练中实现超高的计算能力,处理大型复杂的神经网络模式,同时扩展带宽,减少延迟,节省成本。这就需要Dojo超级计算机的布局达到空间和时间的最佳平衡。如图所示,Dojo超级计算机的关键单元是——D1芯片,这是一种由Tesla自主研发的神经网络训练芯片。D1芯片采用分布式结构和7 nm工艺,配备500亿个晶体管和354个训练节点。仅内部电路就长达17.7公里,实现了超强计算能力和超高带宽。
6
D1芯片技术参数
7
如图所示,Dojo超级计算机的单个训练模块由25个D1芯片组成。由于各个D1芯片无缝连接在一起,相邻芯片之间的延迟极低,训练模块最大程度实现了带宽预留,配合特斯拉自创的连接器,高带宽低延迟;在不足1立方英尺的体积内,运算能力高达9PFLOPs(9万亿次),I/O带宽高达36 TB/s,12月10日,特斯拉在北京举办了主题为“自动驾驶仿生大脑”的“T-talk”线下分享研讨会。特斯拉主要讲解了AI技术的最新进展,包括特斯拉如何以纯视觉方案实现精准的自动驾驶能力,带来比雷达+视觉融合方案更安全可靠的体验,以及独特的智能算法等独家内容,引领与会者深入了解特斯拉在自动驾驶领域的探索。坚持视觉感知,用AI神经网络技术提升辅助驾驶能力如图1所示。安德烈说:“我们希望建立一个类似于动物视觉皮层的神经网络连接,来模拟大脑信息输入和输出的过程。就像光线进入视网膜一样,我们希望通过相机模拟这一过程。”
相机模拟人类图像处理流程,以指示多任务学习神经网络架构。八个摄像头传输的原始数据通过一个骨干网络进行处理,利用RegNet残差网络和BiFPN算法模型进行统一处理,得到各种不同精度的图像特征,供不同需求的神经网络任务使用。
HydraNets是一种多任务学习神经网络架构,由于它处理的是单个相机的单帧图像,因此在实际应用中遇到了许多瓶颈。因此,在二级结构中加入了Transformer神经网络结构,使得原来提取的二维图像特征变成了由多个摄像头组装的三维向量空间的特征,从而大大提高了识别率和准确率。还没有,因为还是单帧画面,所以需要时间维度和空间维度,让车辆具备特征“记忆”功能,以应对“遮挡”、“路牌”等各种场景,最终以视频流的形式实现行驶环境的特征提取,形成向量空间,让车辆低延迟的准确判断周围环境,形成4D向量空间。这些视频特征的数据库是自动用于训练的。
视频4D向量空间的神经网络架构然而,由于城市自动驾驶和高速自动驾驶的区别,车辆规划模块存在两大问题。一个是驾驶方案不一定有最优解,它的局部最优解会很多,也就是说在同样的驾驶环境下,自动驾驶可以选择很多可能的解,而且都是好的解;其次,维度高,车辆不仅需要做出即时反应,还需要对下一段时间进行规划,预估位置、空间、速度、加速度等大量信息。因此,特斯拉选择了两种方式来解决规划模块的两大问题。一种是通过离散搜索求解局部最优解的“答案”,以每1.5毫秒2500次搜索的超级效率执行;另一种是利用连续函数优化来解决高维问题。通过离散搜索得到一个全局最优解,然后通过不断的函数优化平衡舒适性、乘坐舒适性等多个维度的需求,得到最终的规划路径。另外,除了为自己规划之外,还要对其他物体的规划进行“预估”和猜测,即以同样的方式,基于对其他物体的识别和速度、加速度等基本参数,再为其他车辆规划路径,并做出相应的反应。但是,世界各地的路况千变万化,非常复杂。如果采用离散搜索方式,会消耗大量资源,决策时间过长。所以选择深度神经网络和蒙特卡罗搜索树相结合,大大提高了决策效率,几乎一个数量级。
不同模式下效率最终规划模块的整体架构如图5所示。首先将数据处理到一个基于纯视觉方案架构的4D向量空间,然后基于之前获得的物体识别和共享特征数据,利用深度神经网络寻找全局最优解,将最终的规划结果交给执行器执行。
视觉识别+规划,实施整体架构,当然再好的神经网络架构和处理方法,都离不开一个有效而庞大的数据库。在从2D到3D、4D的数据转换过程中,1000多人的人工标注团队也在与时俱进地在4D空间进行标注,在矢量空间标注后,会自动映射成不同摄像头的特定单幅图像,大大增加了数据标注量,但这些还远远不够,人工标注的数据量远远不够自动驾驶所需的训练。
4D向量空间手动标注演示由于人更擅长语义识别,而计算机更擅长几何、三角剖分、跟踪和重建,特斯拉想创造一种人与计算机“和谐分工”的模式。特斯拉建立了一个庞大的自动标注管道,使用45秒-1分钟的视频,包括大量的传感器数据,交给神经网络进行离线学习,然后使用大量的机器和人工智能算法生成可以用来训练网络的标注数据集。
视频剪辑的自动标记过程用于识别可驾驶区域,例如道路、车道、十字路口等。特斯拉使用NeRF“神经辐射场”,即一种将2D转换为3D的图像处理算法,给出已建立的XY坐标点数据,使神经网络可以预测地面的高度,从而生成无数的XYZ坐标点和各种语义,如路边、车道线、路面等。,形成大量信息点,投射回相机屏幕。然后将道路数据与前面神经网络识别出的分割结果进行对比,整体优化所有摄像头的图像;同时结合时间维度和空间维度,营造出相对完美的重建场景。
道路重建演示就是利用这种技术,对经过同一地点的不同车辆所重建的道路信息进行交叉比对。只有所有的位置信息都一致,预测才是正确的。在共同作用下,形成了一种有效的路面标注方法。
多视频数据标注相互重叠,相互检查,与高精地图完全不同。只要所有视频片段生成的标注信息越来越准确,与视频中的实际路况一致,就没有必要维护这些数据。同时,利用这些技术,可以对静态物体进行识别和重建,并根据这些有无纹理的3D信息点对其进行标注。这些标记点对于摄像机识别任何障碍物非常有用。
对这些数据进行离线处理,并对静态物体进行3D信息点重建的另一个好处是,自行车网络一次只能预测其他运动的东西,而离线可以因为已经建立的数据而熟悉过去和未来,可以根据确定的数据预测、标定和优化所有物体的速度和加速度,无论遮挡与否,并对其进行标记。训练网络后期可以更准确的判断其他移动的东西,方便规划模块进行规划。
0
离线校对并标记车辆和行人的速度和加速度,然后将这些结合起来,形成视频数据中所有与道路相关的静态和动态物体的识别、预测和重建,并标记其动态数据。
1
视频片段对周围环境的重构和标注将成为训练自动驾驶神经网络的核心部分。其中一个项目就是用这些数据在三个月内训练好网络,成功实现毫米波雷达的所有功能,并且更加精确,于是去掉了毫米波雷达。
2
在摄像头几乎看不到的情况下,对速度和距离的判断仍然准确验证了这种方法的高效性,因此需要大量的视频数据进行训练。所以与此同时,特斯拉还开发了“模拟场景技术”,可以模拟现实中不常见的“边缘场景”进行自动驾驶训练。如图4所示,在仿真场景中,特斯拉工程师可以提供不同的环境和其他参数(障碍物、碰撞、舒适度等。),大大提高了训练效率。
3
模拟场景特斯拉已经使用模拟模式来训练网络。它已经使用了3亿张图片和50亿个标签来训练网络,并将继续使用这种模式来解决更多的问题。
4
模拟模式带来的提升,以及未来几个月的期待,综上所述,要想更快的提升自动驾驶网络的能力,需要处理大量的视频片段和操作。举个简单的例子,为了去掉毫米波雷达,处理了250万个视频片段,生成了100多亿个标注;而这些使得硬件越来越成为发展速度的瓶颈。此前,特斯拉使用了一套约3000个GPU、略少于20000个CPU的训练硬件,并增加了2000多台FSD计算机进行模拟。后来发展成为由10000个GPU组成的世界排名第五的超级计算机,但即便如此,仍然远远不够。
5
目前在用的超级计算机的参数和变化,所以特斯拉决定自己研发超级计算机。“工程开山之作”——D1芯片和Dojo超级计算机目前,随着待处理数据的指数级增长,特斯拉也在提高训练神经网络的计算能力,于是有了特斯拉Dojo超级计算机。特斯拉的目标是在人工智能训练中实现超高的计算能力,处理大型复杂的神经网络模式,同时扩展带宽,减少延迟,节省成本。这就需要Dojo超级计算机的布局达到空间和时间的最佳平衡。如图所示,Dojo超级计算机的关键单元是——D1芯片,这是一种由Tesla自主研发的神经网络训练芯片。D1芯片采用分布式结构和7 nm工艺,配备500亿个晶体管和354个训练节点。仅内部电路就长达17.7公里,实现了超强计算能力和超高带宽。
6
D1芯片技术参数
7
如图所示,Dojo超级计算机的单个训练模块由25个D1芯片组成。由于各个D1芯片无缝连接在一起,相邻芯片之间的延迟极低,训练模块最大程度实现了带宽预留,配合特斯拉自创的连接器,高带宽低延迟;在不到1立方英尺的体积内,计算能力高达9PFLOPs(9万亿次),I/O带宽高达36 TB/s. 6
由D1芯片组成的训练模块
7
培训模块的现场演示得益于培训模块的独立运行能力和无限链接能力。由其组成的Dojo超级计算机的性能扩展理论上没有上限,是不折不扣的“性能怪兽”。如图9所示,在实际应用中,特斯拉会将120个训练模块组装成ExaPOD,这是世界领先的人工智能训练计算机。与业内其他产品相比,同等成本下性能提升4倍,同等能耗下提升1.3倍,空间节省5倍。
8
培训模块被组合到ExaPOD中,以匹配强大的硬件,这是由Tesla-Dojo处理单元开发的分布式系统。DPU是一款可视化交互软件,可以根据需求随时调整规模,高效处理和计算,执行数据建模、存储分配、布局优化、分区扩展等任务。很快,特斯拉将开始Dojo超级计算机的第一次组装,并从整个超级计算机到芯片和系统进一步完善。对于人工智能技术,马斯克显然有更远大的追求。这种追求寄托在他开场白中“我们遇到了一些技术难题,希望未来用AI解决”的调侃上,更重要的是,在活动的最后,他承诺“我们将进一步畅游整个人类世界”。6
由D1芯片组成的训练模块
7
培训模块的现场演示得益于培训模块的独立运行能力和无限链接能力。由其组成的Dojo超级计算机的性能扩展理论上没有上限,是不折不扣的“性能怪兽”。如图9所示,在实际应用中,特斯拉会将120个训练模块组装成ExaPOD,这是世界领先的人工智能训练计算机。与业内其他产品相比,同等成本下性能提升4倍,同等能耗下提升1.3倍,空间节省5倍。
8
培训模块被组合到ExaPOD中,以匹配强大的硬件,这是由Tesla-Dojo处理单元开发的分布式系统。DPU是一款可视化交互软件,可以根据需求随时调整规模,高效处理和计算,执行数据建模、存储分配、布局优化、分区扩展等任务。很快,特斯拉将开始Dojo超级计算机的第一次组装,并从整个超级计算机到芯片和系统进一步完善。对于人工智能技术,马斯克显然有更远大的追求。这种追求寄托在他开场白中“我们遇到了一些技术难题,希望未来用AI解决”的调侃上,更重要的是,在活动的最后,他承诺“我们将进一步畅游整个人类世界”。
2021年12月10日,由雷峰网amp新智驾主办的第四届全球智能驾驶峰会在深圳正式召开。
1900/1/1 0:00:00中国汽车工业协会发布了电动汽车冬季用车指南来消除车主的里程焦虑。并从电池活性、平稳驾驶等方面给出了建议。
1900/1/1 0:00:00盖世汽车讯12月16日,人工智能(AI)芯片制造商Hailo宣布与恩智浦半导体(NXPSemiconductors)合作,推出一系列用于汽车电子控制单元(ECU)的联合AI解决方案。
1900/1/1 0:00:00近日,媒体从雷丁汽车官方渠道了解到,旗下全新产品雷丁芒果Pro4门款将于12月20日正式开启预售。与此同时,“雷丁芒果盒用户体验中心”也将同步落地,新车新形象的双重惊喜还是非常值得期待的。
1900/1/1 0:00:0012月15日,蔚来官方发布,G50沪渝高速换电网络全线正式打通。这是继G1京哈高速、G2京沪高速、G4京港澳高速、G60沪昆高速沪湘段后第五条打通的高速换电网络。
1900/1/1 0:00:00日前,马勒开发了一种创新的燃料电池冷却器内涂层,它兼具高操作安全性和高冷却性能,且能延长电池冷却器使用寿命。新的涂层不需要重金属或其他对环境有害的化学物质。
1900/1/1 0:00:00