据新浪科技北京时间1月26日报道,据外媒报道,从Fortran到arXiv.org,这些计算机代码和平台使生物学、气候科学和物理学等学科的发展真正“迅速变化”。2019年,视界望远镜团队让世界第一次看到了黑洞。然而,研究人员发布的发光圆形物体的图像并不是传统的图像,而是经过计算的图像。研究人员利用位于美国、墨西哥、智利、西班牙和南极洲的射电望远镜的数据进行了数学转换,最终合成了这幅具有里程碑意义的图像。研究团队还发布了用于实现这一壮举的编程代码,并写了一篇文章记录了这一发现,其他研究人员可以在此基础上进一步分析。

如果没有能够解决研究问题的软件,也没有知道如何编写和使用软件的研究人员,这种无论计算机多么强大的模式都越来越普遍。从天文学到动物学,现代每一项重大科学发现的背后都有计算机的参与。美国斯坦福大学的计算生物学家Michael Levitt与另外两名研究人员分享了2013年诺贝尔化学奖,因为他“为复杂化学系统创建了多尺度模型”。他指出,今天="世纪,发现,曼,现代,远程“src=”/eimg/jndp/ig/20230309191020030364/2.jpg“/>
Murchison Wide Field Array是一个位于澳大利亚西部的射电望远镜阵列,其部分夜景使用快速傅立叶变换来收集数据。1965年,美国数学家詹姆斯·库利和约翰·杜基提出了一种加速这一过程的方法。快速傅立叶变换通过递归将计算傅立叶变换的问题简化为N个log2步骤。随着N的增加,速度也会增加。对于1000个点,速度增加大约是100倍;一百万分等于五万次。这个“发现”实际上是一个重新发现,因为德国数学家高斯在1805年研究过它,但他从未发表过。詹姆斯·库利和约翰·杜基做到了。他们开始了傅里叶变换在数字信号处理、图像分析、结构生物学等领域的应用,成为应用数学和工程领域的重大事件之一。FFT已经多次应用于代码中,近年来流行的解决方案是FFTW,它被认为是世界上最快的FFT。加州劳伦斯伯克利国家实验室分子生物物理和综合生物成像系主任保罗·亚当斯回忆说,1995年他改进细菌蛋白凝胶的结构时,即使使用FFT和超级计算机,也需要“很多小时,甚至几天”才能计算。“如果我试图在没有FFT的情况下做到这一点,我不知道在现实中该怎么做,”他说。“这可能需要很长时间。”分子编目:生物数据库数据库是当今科学研究不可或缺的一部分,因此人们很容易忘记它们也是软件驱动的。在过去的几十年里,数据库资源的规模迅速扩大,影响了许多领域,但也许没有哪个领域的变化比生物学领域的变化更引人注目。
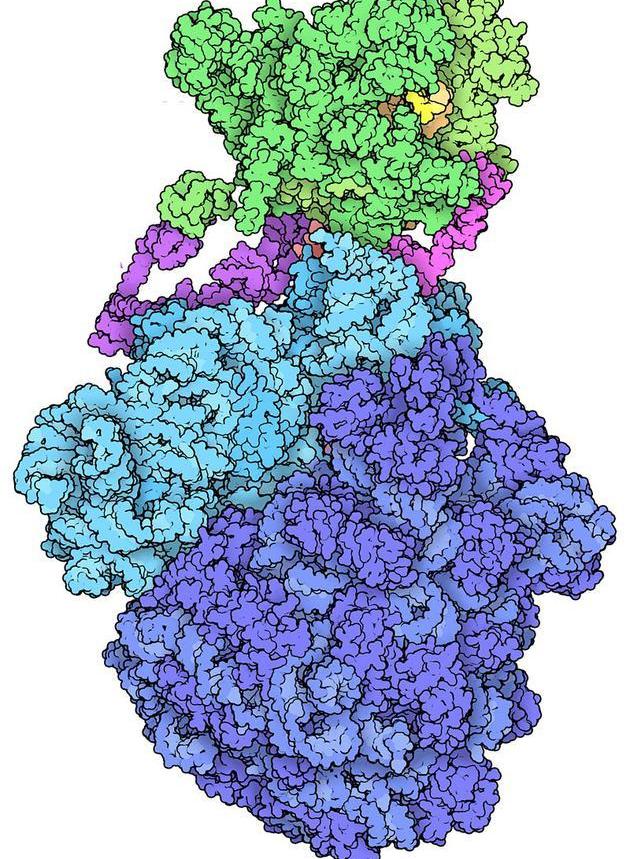
蛋白质数据库有超过17万个分子结构文件,包括这种细菌的“表达者”,其功能是将RNA和蛋白质合成过程结合起来。如今,科学家使用的庞大基因组和蛋白质数据库来自美国物理化学家Margaret Dahoff的工作,她也是生物信息学领域的先驱。20世纪60年代初,当生物学家致力于整理蛋白质的氨基酸序列时,戴霍夫开始组织这些信息,以寻找不同物种之间进化关系的线索。1965年,她和三位合著者发表了《蛋白质序列和结构图谱》,描述了当时已知的65种蛋白质的序列、结构和相似性。历史学家Bruno Strasser在2010年写道,这是第一个“与特定研究问题无关”的数据集,它将数据编码在穿孔卡片中,使扩展数据库和搜索成为可能。其他“计算机化”的生物数据库紧随其后。蛋白质数据库于1971年投入使用,目前已详细记录了17万多个大分子结构。加州大学圣地亚哥分校的进化生物学家Russell Doolittle于1981年创建了另一个名为Newat的蛋白质数据库。1982年,美国国立卫生研究院与多个机构合作建立了GenBank数据库,这是一个开放获取的DNA序列数据库。这些数据库资源在1983年7月证明了它们的价值。当时,由伦敦帝国癌症研究基金会(Imperial Cancer Research Foundation)蛋白质生物化学家迈克尔·沃特菲尔德(Michael Waterfield)领导的团队和杜利特(DuLittle)团队独立报告了一种特殊的人类生长因子序列和一种导致猴子癌症的病蛋白之间的相似性。观察结果证明了病诱导的肿瘤机制——通过模仿生长因子,病诱导不受控制的细胞生长。国家生物技术信息中心(National Center for Biotechnology Information)前主任詹姆斯·奥斯特(James Oster)表示:“这一结果启发了一些对计算机和统计不感兴趣的生物学家:我们可以通过比较序列来了解一些有关癌症的信息。”奥斯特还表示,这一发现标志着“客观生物学的到来”。除了设计实验来验证特定的假设外,研究人员还可以挖掘公共数据集,并找到那些实际收集数据的人可能没有预料到的联系。当不同的数据集连接在一起时,这种能力将迅速增加。例如,NCBI程序员在1991年通过Entrez实现了这一点;
Entrez是一种允许研究人员自由搜索和比较DNA、蛋白质和文献的工具。预测领导者:在第二次世界大战结束时,计算机先驱约翰·冯·诺依曼开始将几年前用于计算弹道轨迹和武器设计的计算机转向天气预测问题。在那之前,“天气预报只是实证的,”Shulang Zhenguo解释道,他利用经验和直觉来预测接下来会发生什么。相比之下,冯·诺依曼的团队“试图根据物理定律进行数值天气预测”。位于新泽西州普林斯顿的美国国家海洋和大气管理局地球物理流体动力学实验室建模系统部门负责人Venkatramani Balaji表示,这些方程几十年来一直为人所知。但早期的气象学家无法解决这些问题。为了实现这一点,有必要输入当前条件,计算它们在短时间内将如何变化,并重复它们。这个过程非常耗时,以至于在实际天气条件出现之前无法完成数学计算。1922年,数学家刘易斯·弗莱·理查森花了几个月的时间计算了德国慕尼黑的6小时预报。根据历史记录,他的结果“极不准确”,包括“在任何已知的土地条件下都不可能发生”的预测。计算机使这个问题很容易解决。20世纪40年代末,冯·诺依曼在普林斯顿高等研究院成立了一个天气预报团队。1955年,第二个团队,地球物理流体动力学实验室,开始了他所说的“无限预测”,即气候建模。振国树郎于1958年加入气候建模团队,开始研究大气模型;
他的同事柯克·布莱恩将这个模型应用于海洋研究。1969年,他们成功地将两者结合在一起,并在2006年创造了《自然》杂志所称的科学计算的“里程碑”。今天的模型可以将地球表面划分为25公里×25公里的正方形,并将大气层划分为几十层。相比之下,Shulang Zhenguo和Brian开发的海洋-大气联合模型的面积为500平方公里,将大气分为九个层次,仅覆盖地球的六分之一。尽管如此,Venkatramani Balaji表示“这个模型做得很好”,使研究团队首次能够通过计算机预测二氧化碳水平上升的影响。数字计算机:BLAS科学计算通常涉及使用向量和矩阵进行相对简单的数学运算,但这样的向量和矩阵太多了。但在20世纪70年代,还没有公认的计算工具来进行这些计算。因此,从事科学工作的程序员会花时间为基本的数学运算设计高效的代码,而不是专注于科学问题。

加州劳伦斯利弗莫尔国家实验室的Cray-1超级计算机。在1979年BLAS编程工具问世之前,研究人员在Cray-1超级计算机和其他机器上工作还没有线性代数标准。编程世界需要一个标准。1979年,出现了这样一个标准:基本线性代数汇编。这是一个应用程序接口标准,用于标准化数字库,用于发布基本的线性代数运算,如向量或矩阵乘法。这个标准发展到1990年,为向量数学和后来的矩阵数学定义了几十个基本例程。田纳西大学计算机科学家、BLAS开发团队成员Jack Dongarra表示,事实上,BLAS将矩阵和向量数学简化为与加法和减法一样基本的计算单元。得克萨斯大学奥斯汀分校的计算机科学家Robert van de Geijn指出,BLAS“可能是为科学计算定义的最重要的接口”。除了为常用函数提供标准化名称外,研究人员还可以确保基于BLAS的代码在任何计算机上以相同的方式工作。该标准还使计算机制造商能够优化BLAS的安装和启用,以便在其硬件上快速操作。40多年来,BLAS一直代表着科学计算堆栈的核心,即运行科学软件的代码。Lorena Barba是美国乔治华盛顿大学的机械和航空航天工程(603698,Guba)教师,她称之为“五层代码中的机器”。Jack Dongarra说:“它为我们的计算提供了基础设施。
必要的显微镜:20世纪80年代初,美国国立卫生研究院图像程序员Wayne Rasband在马里兰州贝塞斯达的美国国立卫生院脑成像实验室工作。实验室有一台扫描仪,可以将X射线数字化,但不能在计算机上显示或分析。为此,拉斯班德编写了一个程序。这个程序是专门为价值15万美元的PDP-11小型计算机设计的。这是一台安装在架子上的电脑,显然不适合个人使用。然后,在1987年,苹果公司发布了Macintosh II,这是一个更用户友好、更实惠的选择。Rasband说,“在我看来,这显然是一个更好的实验室图像分析系统。”他将软件转移到一个新的平台上,并将其重命名,以建立一个图像分析生态系统。NIH图像及其后续版本使研究人员能够在任何计算机上查看和量化几乎任何图像。这个软件系列包括ImageJ,一个由Lassband为Windows和Linux用户编写的基于Java的版本;
还有Fiji,这是ImageJ的发行版,由德国德累斯顿马克斯·普朗克分子细胞生物学和遗传学研究所的Pavel Tomancak团队开发,包括关键插件。布罗德研究所成像平台上的计算生物学家贝丝·奇米尼说:“ImageJ无疑是我们拥有的最基本的工具。”。“我从未与使用过显微镜的生物学家交谈过,但从未使用过ImageJ或斐济。”

ImageJ工具在插件的帮助下,可以自动识别显微镜图像中的细胞核,这可能部分是因为这些工具是免费的。但威斯康星大学麦迪逊分校的生物医学工程师Kevin Eliceiri指出,另一个原因是用户可以根据自己的需求轻松定制工具。自从Rasbande退休以来,Kevin Eliceiri的团队一直在领导ImageJ的开发。ImageJ提供了一个看似简单、简约的用户界面,自20世纪90年代以来基本保持不变。然而,由于其内置的宏记录器、广泛的文件格式兼容性和灵活的插件架构,该工具具有无限的可扩展性。该团队的编程总监柯蒂斯·鲁登表示,“数百人”为ImageJ贡献了插件。这些新添加的功能极大地扩展了研究人员的工具集,例如跟踪视频中的对象或自动识别细胞的能力。Kevin Eliceiri说:“这个程序的目的不是实现一切或结束一切,而是为用户的目标服务。与Photoshop和其他程序不同,ImageJ可以是你想要的任何东西。”序列查找器:BLAST在解释文化方面可能比把软件名称变成动词更重要。说到搜索,你会想到谷歌;
当谈到遗传学时,研究人员立刻想到BLAST。通过替换、删除、删除和重排等方法,生物体将进化变化蚀刻成分子序列。发现序列之间的相似之处,特别是蛋白质之间的相似性,可以让研究人员发现进化关系,并对基因功能有更深入的了解。在快速扩展的分子信息数据库中,要快速准确地实现这一点并不容易。玛格丽特·达霍夫在1978年取得了重大进展。她设计了一个“点接受突变”矩阵,使研究人员不仅可以评估两个蛋白质序列的相似性,还可以根据进化距离评估它们的系统发育关系。1985年,弗吉尼亚大学的William Pearson和NCBI的David Lipman引入了FASTP,这是一种结合了Daihoff矩阵和快速搜索功能的算法。几年后,Lipman与NCBI的Warren Gish和Stephen Atshul、宾夕法尼亚州立大学的Weber Miller和亚利桑那大学的Gene Miles共同开发了一种更强大的改进技术BLAST。BLAST于1990年发布,将处理快速增长的数据库所需的搜索速度与提取进化上更遥远的匹配结果的能力相结合。同时,该工具还可以计算这些匹配发生的概率。阿特舒尔说,计算结果很快就会出来。“你可以输入搜索内容,喝一口咖啡,搜索就完成了。”但更重要的是,BLAST很容易使用。在一个通过邮件更新数据库的时代,Warren Gish建立了一个电子邮件系统,后来又建立了一种基于网络的架构,允许用户在NCBI计算机上远程运行搜索,确保搜索结果始终是最新的。哈佛大学计算生物学家Sean Eddie表示,BLAST系统为当时基因组生物学的胚胎领域提供了一种革命性的工具,即根据相关基因找出未知基因可能的功能的方法。对于各个地区的测序实验室来说,它也提供了一个新颖的动词。“这是名词转化为动词的众多例子之一,”Eddie说。“你会说你正在准备对你的序列进行BLAST。”预打印平台:arXiv.org在20世纪80年代末,高能物理学家经常将他们提交的论文副本邮寄给同行征求意见,但只邮寄给少数人。物理学家Paul Kingspag在2017年写道:“处于食物链较低地位的人依赖一线研究人员的成就,而非精英机构中有抱负的研究人员往往处于特权圈之外。”1991年,在新墨西哥州洛斯阿拉莫国家实验室工作的Kingspag编写了一个电子邮件自动回复程序,希望建立一个公平的竞争环境。订阅用户每天都会收到一份预印本列表,每一篇文章都有一个文章标识符。只需一封电子邮件,来自世界各地的用户就可以从实验室计算机系统提交或检索论文,获取新论文列表,或按作者或标题进行搜索。
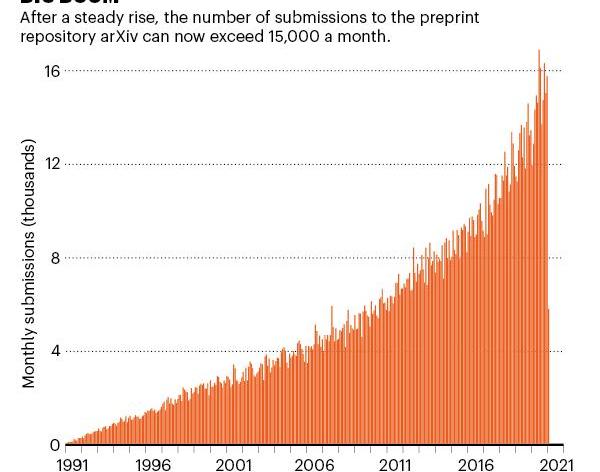
ArXiv成立近30年,预印本约180万份,全部免费提供,每月提交论文1.5万多篇,下载量3000万次。Kingspag的计划是将论文保存三个月,并将内容限制在高能物理上。但一位同事说服他无限期地保留这些文章。他说,“那一刻,它从公告栏变成了档案馆。”于是,来自各个领域的文件开始蜂拥而至。1993年,金斯伯格将该系统迁移到互联网上,并于1998年将其命名为arXiv.org,至今仍在使用。ArXiv成立近30年,拥有约180万份预印本,所有预印本都是免费提供的。此外,每月提交的论文超过15000篇,下载次数达到3000万次。十年前,《自然光子学》杂志的编辑在评论arXiv成立20周年时写道:“不难看出arXiv的服务为什么如此受欢迎。这个系统可以让研究人员快速轻松地插上旗帜来展示他们的工作,同时避免了提交传统同行评审期刊的麻烦和时间成本。”。“arXiv网站的成功也促进了生物学、医学以及社会学和其他学科中类似预印本网站的繁荣。这种效果可以从今天出版的数以万计的新冠肺炎预印本中看到。”我很高兴看到,30年前,在粒子物理世界之外,这种方法被认为是异端的,但现在它被普遍认为是朴素自然的,“杜松子酒……
说。“从这个意义上说,这就像一个成功的研究项目。”数据浏览器:IPython Notebook 2001年,Fernando Peres还是一名研究生,他希望“寻找拖延症”。当时,他决定采用Python的一个核心组件。Python是一种解释性语言,这意味着程序是逐行执行的。程序员可以使用一种称为“读取-评估-打印循环”的计算调用和响应工具,在该工具中输入代码,然后由解释器执行。REPL允许快速探索和迭代,但Shimon Peres指出Python的REPL并不是为了科学目的而构建的。例如,它不允许用户轻松地预加载代码模块或打开数据可视化。所以西蒙·佩雷斯自己写了另一个版本。其结果是IPython的诞生,这是一个由Shimon Peres于2001年12月推出的“交互式”Python解释器,有259行代码。十年后,西蒙·佩雷斯与物理学家布莱恩·格兰杰和数学家埃文·帕特森合作,将该工具迁移到网络浏览器,推出了IPython
日前,威马汽车创始人、董事长兼CEO沈晖在其微博晒出了2020财年恒大汽车主营构成,并称“恒大汽车就差汽车了”。
1900/1/1 0:00:00日前,网络上流传的一段长城WEY坦克300越野,在河沟“趴窝”的视频,引起了网友们的大量关注与转发。后续,车主证实,车辆的“中央传动轴,直接从分动箱断了出来。
1900/1/1 0:00:00一个人要是没有一个长期的考量,不设计一套具体的行动方案,那怕是只会一事无成,一个企业更是如此。
1900/1/1 0:00:00虽然前段时间一车难求,并且采用直营模式,但是特斯拉也遇到了传统车企的销售难题,就是老款车型清库存。
1900/1/1 0:00:00新浪科技讯1月27日上午消息,据报道,特斯拉即将发布的财报可能会触发向CEO埃隆马斯克支付70亿美元期权,而这只热门股的投资者则迫切希望听到该公司2021年的交付目标。
1900/1/1 0:00:00如果月薪不过万,我们能否拥有一台车?能否拥有一次说走就走的旅行?答案一定是可以的生活中,“诗和远方”并不是奢侈品,也许你只需要一辆旅行车。
1900/1/1 0:00:00