前阵子马斯克发推文称,特斯拉的“AI日”将于北美时间8月19日正式举行。根据他之前的推文,大会将介绍特斯拉在人工智能领域的软硬件进展,尤其是在神经网络的训练和预测推理方面;这项活动的主要目的是吸引相关人才。

这种做法很特斯拉,就像2019年的“自主日”和2020年的“电池日”。估计整个“AI日”的发布会都会涉及到很多软硬件的技术细节,以此向外界“秀肌肉”。而这种技术“秀肌肉”是特斯拉吸引顶尖人才的独特方式。某种程度上,特斯拉举办类似发布会时,面对的群体更多的是业内专业人士;以宏大的规划方向,颠覆性的行业研发成果,吸引那些心潮澎湃的人才。特斯拉AI硬件负责人彼得·班农(Peter Bannon)曾在接受采访时表示:“你知道很多人想在特斯拉工作的根本原因,只是因为他们想从事(FSD)的研发和相关工作。”事实上,最近几年,在统计工程专业学生想去的公司排名中,特斯拉和SpaceX经常排名第一,这其实也证明了彼得所说的。

(Photo /Universum)虽然“AI日”的信息一如既往的没有泄露,但是很多从事AI领域的人已经被上面的预热图激动了。神秘道场电脑芯片在“AI日”发布会的邀请函上有一张夸张的芯片图。从图中估计芯片是非传统封装形式,第一和第五铜结构为水冷散热模块;用红色圈出的第二层由5×5阵列的25个芯片组成;第三层是具有25个阵列核心的BGA封装基板;第四层和第七层应该仅具有附着在物理承载结构上的一些导热性;第六层用蓝色圈起来的应该是电源模块,上面垂直的黑条很可能是通过散热与芯片高速通讯的互联模块;

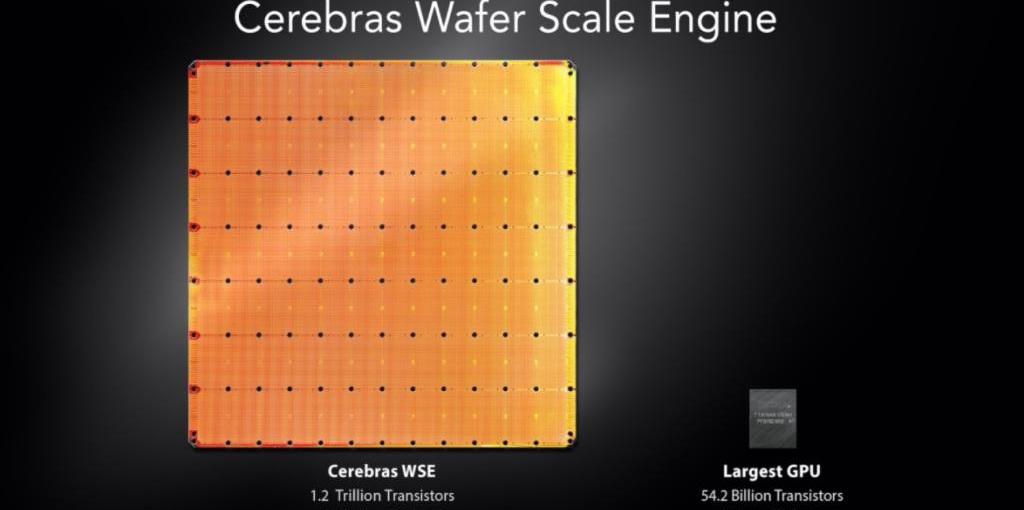
从第二层结构的圆角和拥有25个芯片的结构来看,它与脑波强化器的WSE超级处理器非常相似,即特斯拉可能采用了TSMC的InFO-SoW(集成扇出系统)设计。

所谓InFo-SoW设计,简单来说就是一个晶圆可以“切割”很多芯片,做出CPU/GPU等很多芯片(根据设计不同,芯片类型在光刻时确定),而InFo-SoW是指所有芯片都来自同一个晶圆,不需要切割,直接将整个晶圆做成超大芯片,实现片上系统的设计。

优点有三:极低的通信延迟,巨大的通信带宽,提高的能量效率。简单来说,由于C2C (chip to chip)之间的物理距离极短,通信结构可以直接布置在晶圆上,使用统一的2D网状结构可以实现所有核的互联,实现了C2C通信的超低延迟和高带宽;由于结构上的优势,PDN阻抗更低,能效提高。此外,由于是由多个小芯片组成阵列,通过冗余设计可以避免“良率”的问题,实现小芯片加工的灵活性。比如特斯拉前阵子公布的超级计算机,总共使用了5760个Nvida A100 80GB GPUs,因此需要大量的物理结构来连接这些芯片实现通信,不仅消耗了大量的成本,而且由于连接结构的带宽限制,成为了“木桶短板”,导致整体效率低下和巨大的分散散热问题。

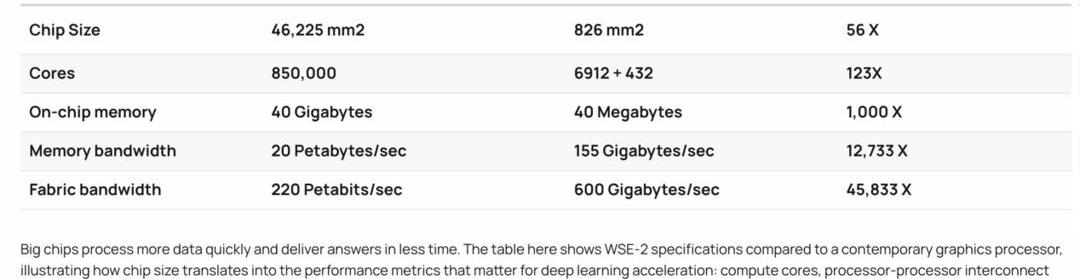
以Cerabraas的WSE-2为参照,一个芯片的核数是Nvdia A100的123倍,芯片缓存是1000倍,缓存带宽是12733倍,Fabric结构带宽是45833倍。
这个级别的性能怪兽主要用途是用于AI的数据处理和训练。其第一代芯片WSE已被许多重量级用户使用,如阿贡国家实验室、劳伦斯利弗莫尔国家实验室、匹兹堡超级计算中心、爱丁堡大学超级计算中心、葛兰素史克、东京电子设备公司等。
全球制药巨头葛兰素史克公司高级副总裁金·布兰森(Kim Branson)称赞了WSE将训练时间减少到1/80的卓越表现。在美国最大的科学和工程研究实验室阿贡国家实验室(Argonne National Laboratory),WSE芯片被用于癌症研究,将癌症模型的实验周转时间减少到1/300以下。因此不难推断,“AI日”邀请函上放出的图片应该是马斯克所说的道场超级计算机的自研芯片。而且有意思的是,发布会是在2021年8月19日举行的,而就在一年前的2020年8月19日,马斯克发了一条推特说:“Dojo V1.0还没完成,估计还要一年。不仅仅是芯片本身的研发难度,还有能效和散热的问题。”

之所以说散热问题难,是因为按照300mm的标准晶圆尺寸,特斯拉道场芯片的单个芯片设计应该和RTX 3090差不多。每个芯片至少有280亿到320亿个左右的晶体管,单个芯片的功耗可以达到250-300w左右,整体功耗在6250-7500 W左右;而TSMC也曾说过InFo-SoW设计的最大功耗约为7000w,也印证了这一点。几个月后,他补充道:“Dojo使用我们自研的芯片和优化的计算架构进行神经网络训练,而不是GPU集群。虽然可能不准确,但我认为Dojo将是世界上最好的超级计算机。”此外,马斯克还在Q1 2021中表示,Dojo是一台为神经网络训练而优化的超级计算机。我们认为就视频数据处理速度而言,Dojo将是世界上最高效的。"

事实上,马斯克早在2019年的“自主日”就提到了Dojo,称Dojo是一台超级计算机,可以利用海量视频(级别)数据做“无监督”的标注和训练。而如果你仔细了解2019年的“自主日”发布会,你会发现,特斯拉推出Dojo超算和自研芯片是必然的,是有计划的,是特斯拉不得不做的事情。换句话说,并不是特斯拉想成为人工智能巨头,而是被逼无奈。为什么是道场?事实上,马斯克在推特中回答了这个问题,大致意思是:“只有解决现实世界的AI问题,才能解决自动驾驶问题...除非我们有很强的AI能力和超强的计算能力,否则根本没有办法...自动驾驶行业的人都很清楚,无数的边缘场景只能通过真实世界的视觉AI来解决,因为整个世界的道路都是按照人类的认知来建立的...一旦我们有了一个AI芯片来解决以上问题,剩下的就只能算是。
0
1
其实马斯克已经说的很清楚了,作者会补充一些知识让大家更容易理解。事实上,自动驾驶最核心、最难解决的问题是“感知”。换句话说,系统对周围驾驶环境的感知越强,其自主驾驶的综合能力就越强;也就是说,从这里开始,行业分为两大流派。一种是以特斯拉和Mobileye为首的纯视觉方案(也有激光雷达方案);此外,所有其他相关公司都希望加入尽可能多的传感器融合方案。这里暂且不讨论哪条路是正确的,因为将来很可能会达到殊途同归的结果。但无论哪种路径,都需要对海量数据进行深度学习,即训练神经网络,从而实现所谓的完全自动驾驶,而这是必经之路。原因很简单。自动驾驶的问题可以理解为处理可能遇到的各种驾驶场景和操作,所以这基本上是“无限”的;如果编程方法有限,所有可能出现的问题永远无法解决,或者说人类的能力根本无法覆盖这么多变化的情况。在早期,各种自动驾驶系统因为没有其他办法,只能以这样一种“死板”的方式开发软件,所以能力非常有限,只能应对相对稳定且限制较多的场景。而如果你想识别各种场景,那么你就需要这个“软件”不断适应和“进化”,这就是使用神经网络进行深度学习的原因。神经网络可以简单理解为通过“仿生学”来模拟人类大脑皮层中神经元的“交流与学习”,从而实现“类人”学习的一种数据处理方式。然而,概念很美好,现实很残酷。
2
1943年,沃伦麦卡洛克和沃尔特皮茨写了一篇关于人工神经网络应该如何工作的论文,并通过使用电路制作了一个简单的模型。后来经过很多人的努力和研发,直到1998年,斯坦福大学的伯纳德·维德罗和马尔西安·霍夫才创造出第一套用于解决实际问题的人工神经网络。
3
1956年,丹尼尔在达特茅斯夏季会议上提出了AI的定义,极大地推动了AI和人工神经网络的发展,被普遍认为是AI元年。当时人们信心满满,认为用不了20年就能造出和人脑几乎一样的AI系统。结果在不断的研究中,发现深度神经网络的算法过于复杂,无从下手。于是我放弃了原来的“大而全”的目标形式,转向执行单一目标的方向。
4
除了对人脑的肤浅认识(至今没有太大的提高),人工神经网络架构和软件算法的限制,更多的是计算能力的问题,即受限于半导体产业的发展。李开复博士在做语音识别功能博士论文的时候,即使他当时用的语音数据库很大,实际上也只有100MB,但是却花了他导师近10万美元,相当于1988年两套房子的价格。如今几Pb的数据,计算能力已经成为制约很多AI发展的瓶颈。这里补充一个知识:不同的处理器芯片有不同的能力。比如CPU更一般的计算可以理解为统帅,负责逻辑上更线性的计算和判断;而GPU则是专门做图像处理的芯片,可以处理大量数据,同时进行矩阵计算。此外,它是一个成熟的量产产品,因此在AI学习中应用广泛。前阵子马斯克发推文称,特斯拉的“AI日”将于北美时间8月19日正式举行。根据他之前的推文,大会将介绍特斯拉在人工智能领域的软硬件进展,尤其是在神经网络的训练和预测推理方面;这项活动的主要目的是吸引相关人才。
这种做法很特斯拉,就像2019年的“自主日”和2020年的“电池日”。估计整个“AI日”的发布会都会涉及到很多软硬件的技术细节,以此向外界“秀肌肉”。而这种技术“秀肌肉”是特斯拉吸引顶尖人才的独特方式。某种程度上,特斯拉举办类似发布会时,面对的群体更多的是业内专业人士;以宏大的规划方向,颠覆性的行业研发成果,吸引那些心潮澎湃的人才。特斯拉AI硬件负责人彼得·班农(Peter Bannon)曾在接受采访时表示:“你知道很多人想在特斯拉工作的根本原因,只是因为他们想从事(FSD)的研发和相关工作。”事实上,最近几年,在统计工程专业学生想去的公司排名中,特斯拉和SpaceX经常排名第一,这其实也证明了彼得所说的。
(Photo /Universum)虽然“AI日”的信息一如既往的没有泄露,但是很多从事AI领域的人已经被上面的预热图激动了。神秘道场电脑芯片在“AI日”发布会的邀请函上有一张夸张的芯片图。从图中估计芯片是非传统封装形式,第一和第五铜结构为水冷散热模块;用红色圈出的第二层由5×5阵列的25个芯片组成;第三层是具有25个阵列核心的BGA封装基板;第四层和第七层应该仅具有附着在物理承载结构上的一些导热性;第六层用蓝色圈起来的应该是电源模块,上面垂直的黑条很可能是通过散热与芯片高速通讯的互联模块;
从第二层结构的圆角和拥有25个芯片的结构来看,它与脑波强化器的WSE超级处理器非常相似,即特斯拉可能采用了TSMC的InFO-SoW(集成扇出系统)设计。
所谓InFo-SoW设计,简单来说就是一个晶圆可以“切割”很多芯片,做出CPU/GPU等很多芯片(根据设计不同,芯片类型在光刻时确定),而InFo-SoW是指所有芯片都来自同一个晶圆,不需要切割,直接将整个晶圆做成超大芯片,实现片上系统的设计。
优点有三:极低的通信延迟,巨大的通信带宽,提高的能量效率。简单来说,由于C2C (chip to chip)之间的物理距离极短,通信结构可以直接布置在晶圆上,使用统一的2D网状结构可以实现所有核的互联,实现了C2C通信的超低延迟和高带宽;由于结构上的优势,PDN阻抗更低,能效提高。此外,由于是由多个小芯片组成阵列,通过冗余设计可以避免“良率”的问题,实现小芯片加工的灵活性。比如特斯拉前阵子公布的超级计算机,总共使用了5760个Nvida A100 80GB GPUs,因此需要大量的物理结构来连接这些芯片实现通信,不仅消耗了大量的成本,而且由于连接结构的带宽限制,成为了“木桶短板”,导致整体效率低下和巨大的分散散热问题。
以Cerabraas的WSE-2为参照,一个芯片的核数是Nvdia A100的123倍,芯片缓存是1000倍,缓存带宽是12733倍,Fabric结构带宽是45833倍。
这个级别的性能怪兽主要用途是用于AI的数据处理和训练。其第一代芯片WSE已被许多重量级用户使用,如阿贡国家实验室、劳伦斯利弗莫尔国家实验室、匹兹堡超级计算中心、爱丁堡大学超级计算中心、葛兰素史克、东京电子设备公司等。
全球制药巨头葛兰素史克公司高级副总裁金·布兰森(Kim Branson)称赞了WSE将训练时间减少到1/80的卓越表现。在美国最大的科学和工程研究实验室阿贡国家实验室(Argonne National Laboratory),WSE芯片被用于癌症研究,将癌症模型的实验周转时间减少到1/300以下。因此不难推断,“AI日”邀请函上放出的图片应该是马斯克所说的道场超级计算机的自研芯片。而且有意思的是,发布会是在2021年8月19日举行的,而就在一年前的2020年8月19日,马斯克发了一条推特说:“Dojo V1.0还没完成,估计还要一年。不仅仅是芯片本身的研发难度,还有能效和散热的问题。”
之所以说散热问题难,是因为按照300mm的标准晶圆尺寸,特斯拉道场芯片的单个芯片设计应该和RTX 3090差不多。每个芯片至少有280亿到320亿个左右的晶体管,单个芯片的功耗可以达到250-300w左右,整体功耗在6250-7500 W左右;而TSMC也曾说过InFo-SoW设计的最大功耗约为7000w,也印证了这一点。几个月后,他补充道:“Dojo使用我们自研的芯片和优化的计算架构进行神经网络训练,而不是GPU集群。虽然可能不准确,但我认为Dojo将是世界上最好的超级计算机。”此外,马斯克还在Q1 2021中表示,Dojo是一台为神经网络训练而优化的超级计算机。我们认为就视频数据处理速度而言,Dojo将是世界上最高效的。"
事实上,马斯克早在2019年的“自主日”就提到了Dojo,称Dojo是一台超级计算机,可以利用海量视频(级别)数据做“无监督”的标注和训练。而如果你仔细了解2019年的“自主日”发布会,你会发现,特斯拉推出Dojo超算和自研芯片是必然的,是有计划的,是特斯拉不得不做的事情。换句话说,并不是特斯拉想成为人工智能巨头,而是被逼无奈。为什么是道场?事实上,马斯克在推特中回答了这个问题,大致意思是:“只有解决现实世界的AI问题,才能解决自动驾驶问题...除非我们有很强的AI能力和超强的计算能力,否则根本没有办法...自动驾驶行业的人都很清楚,无数的边缘场景只能通过真实世界的视觉AI来解决,因为整个世界的道路都是按照人类的认知来建立的...一旦我们有了一个AI芯片来解决以上问题,剩下的就只能算是。
0
1
其实马斯克已经说的很清楚了,作者会补充一些知识让大家更容易理解。事实上,自动驾驶最核心、最难解决的问题是“感知”。换句话说,系统对周围驾驶环境的感知越强,其自主驾驶的综合能力就越强;也就是说,从这里开始,行业分为两大流派。一种是以特斯拉和Mobileye为首的纯视觉方案(也有激光雷达方案);此外,所有其他相关公司都希望加入尽可能多的传感器融合方案。这里暂且不讨论哪条路是正确的,因为将来很可能会达到殊途同归的结果。但无论哪种路径,都需要对海量数据进行深度学习,即训练神经网络,从而实现所谓的完全自动驾驶,而这是必经之路。原因很简单。自动驾驶的问题可以理解为处理可能遇到的各种驾驶场景和操作,所以这基本上是“无限”的;如果编程方法有限,所有可能出现的问题永远无法解决,或者说人类的能力根本无法覆盖这么多变化的情况。在早期,各种自动驾驶系统因为没有其他办法,只能以这样一种“死板”的方式开发软件,所以能力非常有限,只能应对相对稳定且限制较多的场景。而如果你想识别各种场景,那么你就需要这个“软件”不断适应和“进化”,这就是使用神经网络进行深度学习的原因。神经网络可以简单理解为通过“仿生学”来模拟人类大脑皮层中神经元的“交流与学习”,从而实现“类人”学习的一种数据处理方式。然而,概念很美好,现实很残酷。
2
1943年,沃伦麦卡洛克和沃尔特皮茨写了一篇关于人工神经网络应该如何工作的论文,并通过使用电路制作了一个简单的模型。后来经过很多人的努力和研发,直到1998年,斯坦福大学的伯纳德·维德罗和马尔西安·霍夫才创造出第一套用于解决实际问题的人工神经网络。
3
1956年,丹尼尔在达特茅斯夏季会议上提出了AI的定义,极大地推动了AI和人工神经网络的发展,被普遍认为是AI元年。当时人们信心满满,认为用不了20年就能造出和人脑几乎一样的AI系统。结果在不断的研究中,发现深度神经网络的算法过于复杂,无从下手。于是我放弃了原来的“大而全”的目标形式,转向执行单一目标的方向。
4
除了对人脑的肤浅认识(至今没有太大的提高),人工神经网络架构和软件算法的限制,更多的是计算能力的问题,即受限于半导体产业的发展。李开复博士在做语音识别功能博士论文的时候,即使他当时用的语音数据库很大,实际上也只有100MB,但是却花了他导师近10万美元,相当于1988年两套房子的价格。如今几Pb的数据,计算能力已经成为制约很多AI发展的瓶颈。这里补充一个知识:不同的处理器芯片有不同的能力。比如CPU更一般的计算可以理解为统帅,负责逻辑上更线性的计算和判断;而GPU则是专门做图像处理的芯片,可以处理大量数据,同时进行矩阵计算。此外,它是一个成熟的量产产品,因此在AI学习中应用广泛。NPU(神经处理单元)从设计层面针对神经网络学习进行了优化。比如谷歌的TPU,特斯拉的FSD芯片,都属于NPU序列。这些芯片扔掉了类似GPU中不需要的功能,只服务于神经网络需要的数据处理形式,速度和能效高得多。但还是需要区分ASIC(专用集成电路)芯片和FPGA(现场可编程门阵列)芯片,其中ASIC芯片,生产出来后,其运行逻辑和功能是固定的,不可修改,是为某个高能效的任务(软件)而生的;而FPGA是半定制芯片,其运行逻辑可以通过软件改变,可以通过软件修改,所以适合训练和优化,能效低于ASIC芯片。和TPU、FSD一样,都属于ASIC芯片,特斯拉这次发布的Dojo芯片属于FPGA序列。回过头来看,市面上没有符合要求的车载芯片可用,也没有符合要求的超级计算机来更好地利用这些数据。特斯拉想要实现这一切。那时候他只做自己的软硬件。2016年特斯拉成立做FSD芯片的时候,谷歌专属的AI芯片TPU刚刚出来,车载AI芯片几乎没有用。所以很有可能FSD和Dojo的立项时间都不会太远,只是因为能耗和需求,Dojo等到7nm的技术相对成熟了,才开始逐步推进。从另一个纬度理解Dojo的必然性,是从神经网络学习的计算顺序。在2019年的“自主日”发布会上,特斯拉其实已经明确表示要去掉雷达,走向纯视觉,视频级数据直接处理。举个简单的例子,一张1080p的图像,最简单的神经网络结构,如果不使用激活函数(tanh,ReLU)进行数据“优化”,需要超过4万亿次的计算。即使使用激活函数优化的卷积神经网络,其计算量也将达到1.3亿次以上;但如果以视频的形式处理,每秒24帧也有24幅图像,计算量惊人。
0
值得注意的是,自动驾驶收集的数据中,约95%是无效数据,这意味着它对于神经网络训练毫无用处。简单来说,每天做几乎一样的试卷,你是得不到任何提高的。所以,即使特斯拉的车辆只是在某些触发条件下采集一些数据,但获取的数据量仍然非常大,需要针对特斯拉自己的软件进行优化的Dojo来大大提高效率。另外,如上所述,“无监督训练”是Dojo的另一个核心目的,用来大大提高训练效率。在神经网络的训练中,其实大量的研究者都是“专家”。简单理解就是通过不断调整“权重”,让神经网络的判断越来越准确,或者手动标注各种“正确答案”供其学习。这会导致“人”成为效率的短板,大大降低整个流程的训练速度。而如果实现了“无监督训练”,即系统通过海量数据和之前的“学习”结果自动标注和自我调整,那么其效率将在量子层面得到提升。举个简单的例子,谷歌的Alpha Go击败世界围棋大师,相信很多人都知道,也是人工智能在特定领域击败人类的标志性事件。相比之下,Alpha Go经过几年的人工参与调整和标记训练结果,战胜了全球高手。作为无监督训练的例子,Alpha Zero只用了3天就打败了Alpha Go Lee,21天就达到了Alpha Master的水平,40天就超越了所有老版本。综上所述,如果特斯拉完成Dojo的建设,可以以惊人的效率进行海量数据训练,解决各种“边缘场景”问题,加速自动驾驶系统的成熟和完善;更重要的是,特斯拉的软硬件垂直整合度非常高,不仅不受制于人,还可以作为服务对外提供深度学习培训服务。
1
马斯克曾表示,一旦Dojo相对完善,Dojo将作为服务开放,对外提供训练服务,Dojo可以承担几乎所有的机器学习任务。
2
这也是为什么马斯克敢说特斯拉会是未来最大的人工智能公司之一。还会有一件事吗?这一次,特斯拉的“AI日”,不出意外,将把Dojo芯片作为软硬件中最重要的内容引入;当然也会涉及到FSD Beta相关的进展介绍,但根据目前的信息来看,很有可能会推出基于7nm技术的HW4.0新硬件。毕竟在2019年的“自主日”,马斯克表示HW4.0的研发已经进行了一半,所以这次发布会也很有可能借此机会发布新的车载芯片硬件。总之,特斯拉“AI日”发布会很有可能再次在汽车行业乃至AI领域掀起一股浪潮。至于会不会有更多惊喜,到那天就揭晓了。NPU(神经处理单元)从设计层面针对神经网络学习进行了优化。比如谷歌的TPU,特斯拉的FSD芯片,都属于NPU序列。这些芯片扔掉了类似GPU中不需要的功能,只服务于神经网络需要的数据处理形式,速度和能效高得多。但还是需要区分ASIC(专用集成电路)芯片和FPGA(现场可编程门阵列)芯片,其中ASIC芯片,生产出来后,其运行逻辑和功能是固定的,不可修改,是为某个高能效的任务(软件)而生的;而FPGA是半定制芯片,其运行逻辑可以通过软件改变,可以通过软件修改,所以适合训练和优化,能效低于ASIC芯片。和TPU、FSD一样,都属于ASIC芯片,特斯拉这次发布的Dojo芯片属于FPGA序列。回过头来看,市面上没有符合要求的车载芯片可用,也没有符合要求的超级计算机来更好地利用这些数据。特斯拉想要实现这一切。那时候他只做自己的软硬件。2016年特斯拉成立做FSD芯片的时候,谷歌专属的AI芯片TPU刚刚出来,车载AI芯片几乎没有用。所以很有可能FSD和Dojo的立项时间都不会太远,只是因为能耗和需求,Dojo等到7nm的技术相对成熟了,才开始逐步推进。从另一个纬度理解Dojo的必然性,是从神经网络学习的计算顺序。在2019年的“自主日”发布会上,特斯拉其实已经明确表示要去掉雷达,走向纯视觉,视频级数据直接处理。举个简单的例子,一张1080p的图像,最简单的神经网络结构,如果不使用激活函数(tanh,ReLU)进行数据“优化”,需要超过4万亿次的计算。即使使用激活函数优化的卷积神经网络,其计算量也将达到1.3亿次以上;但如果以视频的形式处理,每秒24帧也有24幅图像,计算量惊人。
0
值得注意的是,自动驾驶收集的数据中,约95%是无效数据,这意味着它对于神经网络训练毫无用处。简单来说,每天做几乎一样的试卷,你是得不到任何提高的。所以,即使特斯拉的车辆只是在某些触发条件下采集一些数据,但获取的数据量仍然非常大,需要针对特斯拉自己的软件进行优化的Dojo来大大提高效率。另外,如上所述,“无监督训练”是Dojo的另一个核心目的,用来大大提高训练效率。在神经网络的训练中,其实大量的研究者都是“专家”。简单理解就是通过不断调整“权重”,让神经网络的判断越来越准确,或者手动标注各种“正确答案”供其学习。这会导致“人”成为效率的短板,大大降低整个流程的训练速度。而如果实现了“无监督训练”,即系统通过海量数据和之前的“学习”结果自动标注和自我调整,那么其效率将在量子层面得到提升。举个简单的例子,谷歌的Alpha Go击败世界围棋大师,相信很多人都知道,也是人工智能在特定领域击败人类的标志性事件。相比之下,Alpha Go经过几年的人工参与调整和标记训练结果,战胜了全球高手。作为无监督训练的例子,Alpha Zero只用了3天就打败了Alpha Go Lee,21天就达到了Alpha Master的水平,40天就超越了所有老版本。综上所述,如果特斯拉完成Dojo的建设,可以以惊人的效率进行海量数据训练,解决各种“边缘场景”问题,加速自动驾驶系统的成熟和完善;更重要的是,特斯拉的软硬件垂直整合度非常高,不仅不受制于人,还可以作为服务对外提供深度学习培训服务。
1
马斯克曾表示,一旦Dojo相对完善,Dojo将作为服务开放,对外提供训练服务,Dojo可以承担几乎所有的机器学习任务。
2
这也是为什么马斯克敢说特斯拉会是未来最大的人工智能公司之一。还会有一件事吗?这一次,特斯拉的“AI日”,不出意外,将把Dojo芯片作为软硬件中最重要的内容引入;当然也会涉及到FSD Beta相关的进展介绍,但根据目前的信息,很有可能会推出一款基于7nm技术的全新HW4.0硬件。毕竟在2019年的“自主日”,马斯克表示HW4.0的研发已经进行了一半,所以这次发布会也很有可能借此机会发布新的车载芯片硬件。总之,特斯拉“AI日”发布会很有可能再次在汽车行业乃至AI领域掀起一股浪潮。至于会不会有更多惊喜,到那天就揭晓了。
2021年8月13日近日,中国汽车流通协会联合精真估发布了《2021年上半年中国汽车保值率研究报告》。
1900/1/1 0:00:00盖世汽车讯据外媒报道,一位知情人士透露,印度政府在考虑特斯拉提出的降低该国电动汽车进口关税的建议前,要求特斯拉先增加在当地的采购,并分享详细的生产计划。
1900/1/1 0:00:008月12日,蔚来汽车发布了2021年二季度财报,并同步召开了财报电话会议。
1900/1/1 0:00:00盖世汽车讯8月11日,VishayIntertechnology公司(威世)宣布推出一款新型双向非对称(BiAs)单线ESD保护二极管VCUT0714BHD1。
1900/1/1 0:00:00盖世汽车讯8月12日,人工智能视觉芯片公司Ambarella和车队管理技术公司KeepTruckin宣布,通过采用Ambarella的CV22CVflow边缘人工智能视觉系统芯片(SoC),
1900/1/1 0:00:00盖世汽车讯据上汽乘用车提供的消息,上汽乘用车新能源车型7月销量达到13454辆,实现连续5个月销量破万。同时,根据乘联会数据显示,上汽乘用车新能源车型7月批发销量站稳自主品牌前三位置。
1900/1/1 0:00:00